 Nos certifications
Nos certificationsSEO : 7 techniques avancées pour optimiser son site avec Screaming Frog SEO Spider

Le SEO est bien trop souvent réduit à la poursuite de mot-clés, la production et l’optimisation du meilleur contenu, et l’obtention de liens. Mais c’est aussi beaucoup, beaauuucoup d’analyse. Analyse de son trafic, du maillage interne de son site, de son indexation, du comportement des utilisateurs, de la bonne optimisation de ses pages, des liens façonnant l’environnement de son site, et à peu près la même chose avec les sites de ses concurrents. C’est pourquoi un puissant outil de référencement naturel et d’analyse de site est un atout considérable pour l’optimisation de votre site…
Vous souhaitez vous former au SEO ? Découvrez notre atelier en classe virtuelle sur une journée : formation seo en ligne.
Vous vous en douterez avec le titre de cet article, j’utilise moi-même le logiciel SEO Spider de Screaming Frog (la version gratuite est très complète !) pour mes analyses, et je vais vous montrer 7 techniques liées au référencement naturel pour obtenir des informations capitales pour votre SEO grâce à cet outil. L’outil est téléchargeable gratuitement ici.
Si vous débutez dans l’optimisation technique de sites et que la vue des expressions “hreflang”, “JavaScript”, ou encore “404” vous cause des maux de tête, je vous recommande de jeter un oeil aux ressources additionnelles que j’ai pris soin d’ajouter à la fin de cet article.
Il est maintenant temps de soulever le capot de votre site et de mettre les mains dans le cambouis !
- Trouver des URLs et des liens brisés
- Optimiser son maillage interne
- Repérer les redirections inutiles
- Vérifier comment Google traite certaines de vos pages
- Repérer les erreurs Hreflang lorsque son site est disponible en plusieurs langues
- Identifier le contenu mixte sur son site
- Vérifier la profondeur et l’accessibilité de vos pages
1. Trouver des URLs et des liens brisés

Les URLs brisées (ayant une erreur de type 404) sont bien connues pour être la bête noire des experts SEO. Le code d’erreur 404 est pourtant loin d’être une tragédie pour votre SEO. Il s’agit toutefois d’avoir conscience des pages retournant ce type d’erreur et de s’assurer que leur maillage avec d’autres pages, internes ou externes, ne nuit ni à l’expérience utilisateur, ni à celle des bots parcourant votre site.
Une analyse fréquente de votre site vous permettra de prévenir ces mauvaises expériences.
Comment utiliser SEO Screaming Frog pour identifier les URLs brisées ?
1. Commencez par crawler votre domaine ou une partie de celui-ci.
2. Cliquez sur l’onglet “Response codes” et, sous celui-ci, appliquez le filtre “Client Error (4xx)” pour avoir un aperçu des erreurs 4xx.
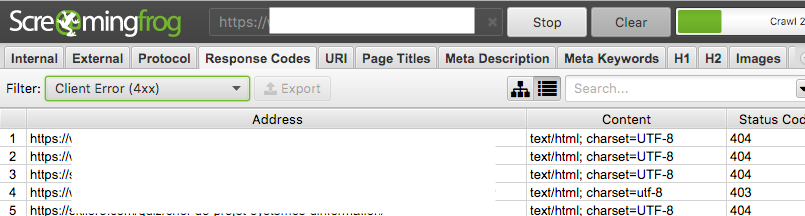
3. Dans le menu, cliquez sur “Bulk export”, “Response Codes” et “Client Error (4xx) Inlinks” pour télécharger un fichier CSV listant toutes ces erreurs.
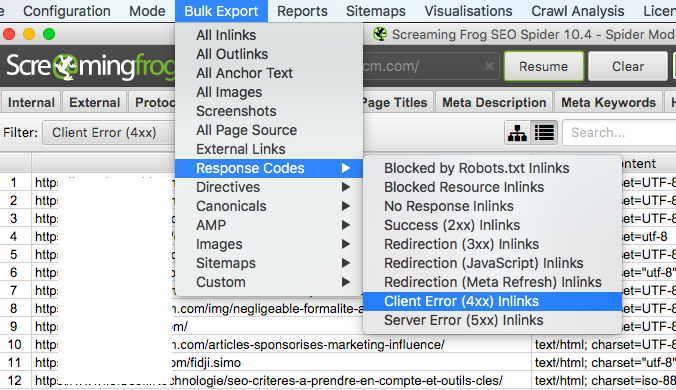
4. Ouvrez le fichier CSV à l’aide de Google Sheets pour identifier les différentes erreurs, leur statut (404, 403, 410 etc.), le type de contenu concerné (image ou AHREF), leur source et leur destination. Ce rapport est d’autant plus utile puisqu’il inclut les liens internes ainsi que les liens sortants.
Vous pouvez suivre la même démarche pour identifier d’autres codes HTTP (3xx et 5xx).
2. Optimiser son maillage interne
Comprendre le maillage de vos URLs est capital pour l’optimisation de votre site. Cela vous permet d’offrir une structure logique à vos utilisateurs et aux bots qui parcourent vos pages.
Il s’agit entre autres de grouper (ou du moins connecter) entre elles les pages abordant le même sujet de manière globale. Lisez l’excellent article d’Olivier Andrieu sur les cocons sémantiques pour mieux comprendre ce qui rend la structure d’un site optimisée.
Comment utiliser SEO Screaming Frog pour obtenir des informations spécifiques sur une URL ?
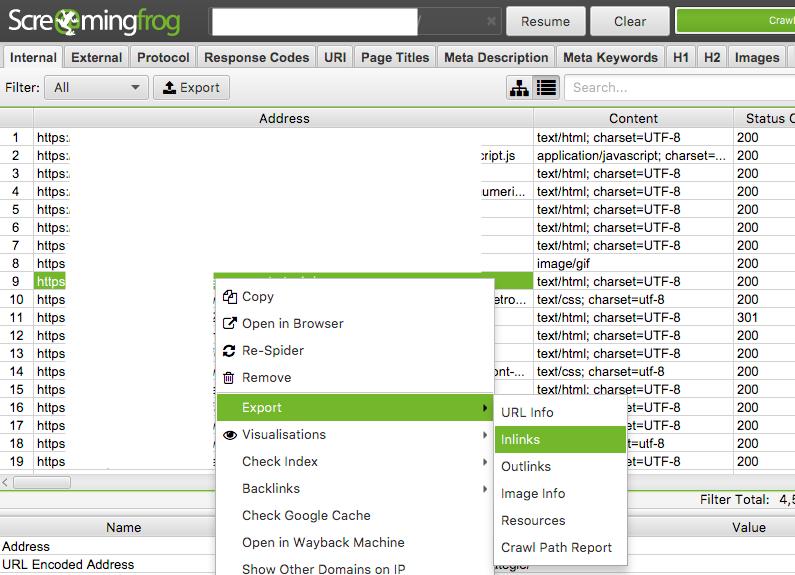
Une fois l’analyse de votre site, ou d’une section de celui-ci, terminée, effectuez un clic droit sur n’importe quel résultat, puis “Export” pour obtenir plusieurs options. Parmi celles-ci, intéressons-nous aux 3 suivantes:
- Inlinks : inclut les liens internes entrants vers l’URL analysée ;
- Outlinks : inclut les liens internes et externes sortants de la page analysée.
Ces informations seront précieuses si vous souhaitez visualiser et structurer vos “topic clusters” (groupes de pages interconnectées autour du même sujet).
3. Repérer les redirections inutiles

Les redirections sont particulièrement utiles pour optimiser le parcours utilisateur en cas de changement de structure.
Toutefois, il est parfois difficile de garder une trace de l’historique de votre site, surtout si celui a déjà quelques années et subit plusieurs modifications. Par conséquent, des chaînes de redirection peuvent indirectement être créées (URL A redirige vers URL B qui elle-même redirige vers URL C).
L’ennui avec ces chaînes de redirection est qu’elles ralentissent les bots dans le parcours de votre site, affectant par la même occasion votre “crawl budget”. Et parce que ce budget est limité, il est important de l’optimiser autant que possible.
Dans ce cas, vous voulez faire en sorte que URL A -> URL B -> URL C devienne URL A > URL C.
Prenez conscience que certaines chaînes de redirection sont même plus subtiles que cela et peuvent être aussi simples que: http://URL-A -> https://URL-A -> https://URL-B
Voici comment repérer ces chaînes à l’aide de Screaming Frog:
1. Après avoir soumis votre site à une analyse, cliquez dans le menu du haut sur “Reports” puis “Redirect Chains” pour télécharger le fichier CSV.

2. Le fichier CSV inclut la source, l’URL concernée et le nombre de redirections jusque l’URL de destination.
Le but est donc de nettoyer un maximum de ces redirections inutiles en remplaçant les URLs de redirections par les URLs de destination.
4. Vérifier comment Googlebot traite certaines de vos pages

Croyez-le ou non : ce que vous voyez sur une page de votre site peut être interprété différemment par les moteurs de recherche. Plusieurs facteurs influencent la manière dont une page est traitée par les navigateurs ainsi que les moteurs de recherche. Parmi ces facteurs l’on retrouve les méthodes et langages de programmation (JavaScript, Ajax, etc.), ainsi que les règles appliquées à votre site (au travers du fichier robots.txt par exemple).
Lorsque vous publiez une nouvelle page, vous devez faire en sorte que celle-ci est proprement rapportée et traitée (le fameux “fetch and render” de Google), surtout si cette page a une structure différente de celles publiées et vérifiées auparavant.
Voici comment s’assurer de la bonne optimisation de votre page sur cet aspect technique :
1.Cliquez sur “Configuration” puis sur “User Agent”
2. Sélectionnez l’une des options GoogleBot

3. Saisissez une URL et commencez l’analyse
4. Cliquez sur l’URL dans les résultats
5. Enfin, sélectionnez l’onglet ‘Rendered Page’ en bas de l’écran
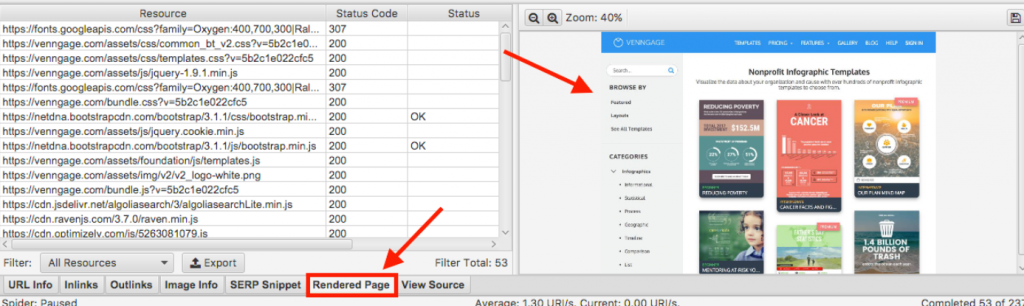
De là vous pouvez voir :
- Une capture d’écran du rendu de la page par GoogleBot
- Chaque ressource de cette page (CSS, JS, images, etc.) ainsi que leur code d’état (200, 307, etc.)
Le gros avantage de cette option est qu’elle vous offre un aperçu rapide de toutes les pages analysées.
5. Repérer les erreurs Hreflang lorsque son site est disponible en plusieurs langues
Pour étendre son activité à l’international, développer des versions de son site en plusieurs langues est forcément encouragé. D’un point de vue technique cependant, il y a de nombreux facteurs à considérer. Parmi ces derniers, l’attribut Hreflang est sûrement le plus important en SEO.
L’attribut Hreflang vous permet de communiquer les variantes linguistiques ou régionales d’une même page aux moteurs de recherche. De cette façon, les internautes seront redirigés vers la version linguistique ou régionale la plus appropriée lors de leurs recherches sur les moteurs.
Et nombreux sont les sites contenant des erreurs à ce niveau !
Voici comment identifier ces erreurs avec l’outil d’analyse Screaming Frog :
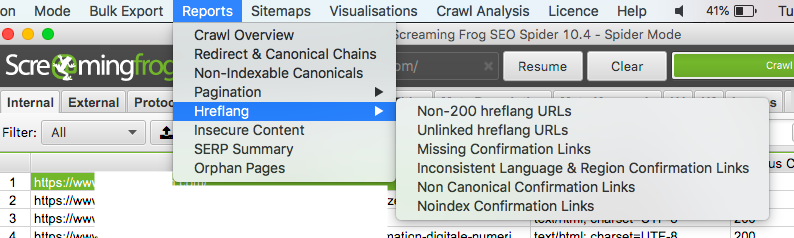
1. Allez dans “Reports” puis “Hreflang” et sélectionnez le type d’erreur que vous souhaitez vérifier.
2. Si le fichier CSV téléchargé est vide, c’est qu’aucune erreur n’a été identifiée par Screaming Frog. Autrement, voici les erreurs les plus communes :
- “Errors” – Ce rapport montre tous les attributs Hreflang ne renvoyant pas de code HTTP de type 200 (aucune réponse, bloqué par le fichier robots.txt, code HTTP de type 3xx, 4xx ou 5xx) ou n’étant pas reliés au site ;
- “Missing Confirmation Links” – Ce rapport montre les pages avec un lien de confirmation manquant, et quelles pages sont concernées.
Note: Ce détail est très important quand il s’agit d’aborder l’internationalisation de ses pages. Il reste pourtant l’une des erreurs les plus fréquentes. Si un rel tag sur une page B inclut une URL spécifique vers une page A, cette même page A doit renvoyer un “lien de confirmation” vers la page B. Un exemple avec le site Venngage Infographies ci-dessous.
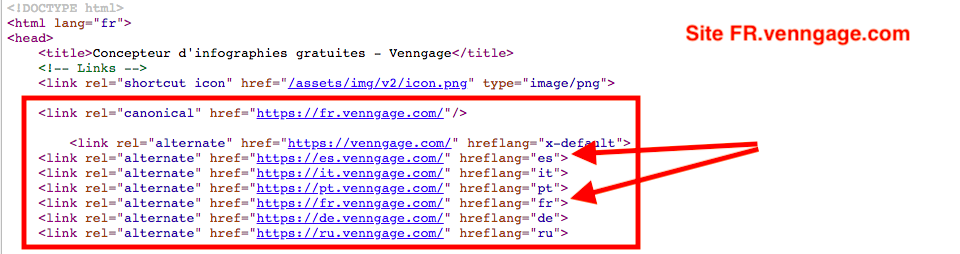
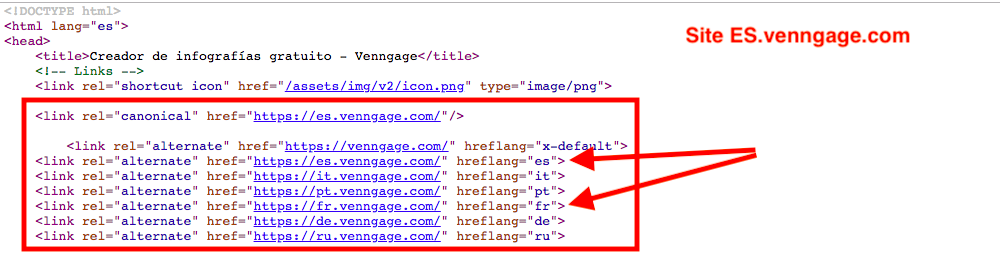
- “Inconsistent Language Confirmation Links” – Ce rapport montre les pages dont les liens de confirmation sont incohérents par rapport à la langue ou la région visée.
- “Non Canonical Confirmation Links” – Ce rapport présente les liens de confirmation qui sont liés à des URLs “non-canoniques” (vous l’aurez deviné : les attributs Hreflang devraient seulement inclure les versions canoniques de vos URLs).
6. Identifier le contenu mixte sur son site
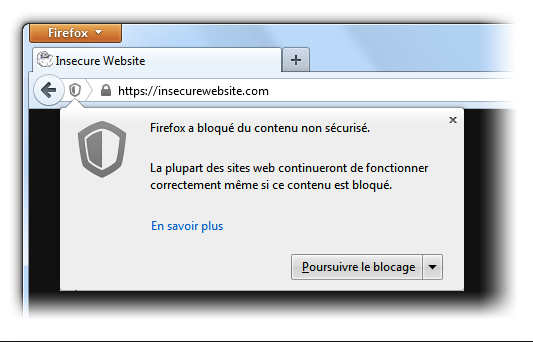
On appelle contenu mixte toute page sécurisée (https) comportant des éléments non-sécurisés (http). Lorsque des moteurs de recherche comme Google repèrent du contenu mixte sur un site, ils considèrent que la sécurisation de l’expérience utilisateur sur ce même site est dégradée.
Les dernières versions des principaux navigateurs avertissent généralement le visiteur d’un site lorsque ce dernier comporte du contenu mixte (à l’aide d’une pop-up, parfois d’une page entière, affichant un message du type “Cette connexion n’est pas sécurisée”).
Voici comment identifier le contenu mixte avec l’outil de référencement naturel Screaming Frog :
1. Cliquez dans le menu du haut sur “Reports” puis “Insecure content” pour télécharger le rapport.
2. Remplacez ces ressources, liens, ou supprimez-les pour augmenter la qualité de votre site.

7. Vérifier la profondeur et l’accessibilité des pages de son site
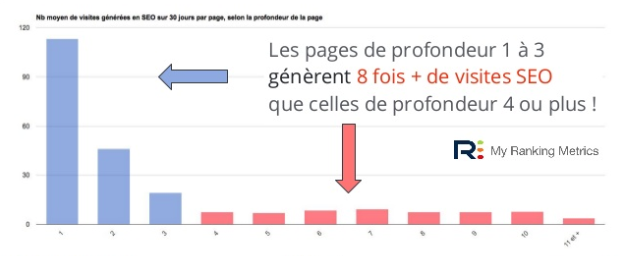
Connaître l’accessibilité de vos pages devrait être, selon moi, un élément crucial de votre stratégie SEO. Une mauvaise structure est souvent caractérisée par des URLs profondes dont le chemin d’accès est incohérent. Un site contenant beaucoup de pages facilement accessibles fera souvent la différence avec un site dont la navigation est maladroite.
Pour optimiser votre site, il vous faut donc à la fois :
- Réduire le plus possible le chemin d’accès à vos pages profondes ;
- Garder la navigation jusqu’à ces mêmes pages cohérentes.
Voici comment vérifier l’accessibilité de vos pages avec SEO Screaming Frog :
1. Lancez l’analyse de votre site puis effectuez un clic droit sur l’une des URLs
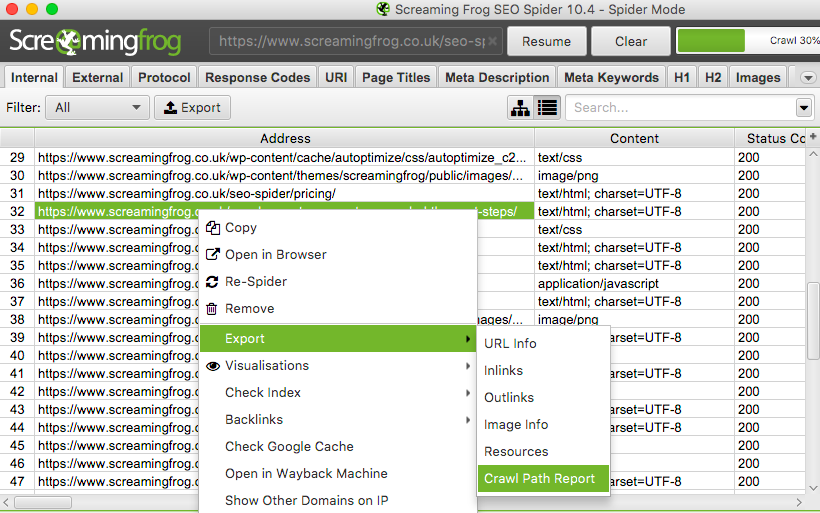
2. Cliquez sur “Export” et sélectionnez “Crawl Path Report”
Ce rapport vous montre le chemin le plus court utilisé par les “spiders” de Google et autres moteurs de recherche pour atteindre vos pages profondes.
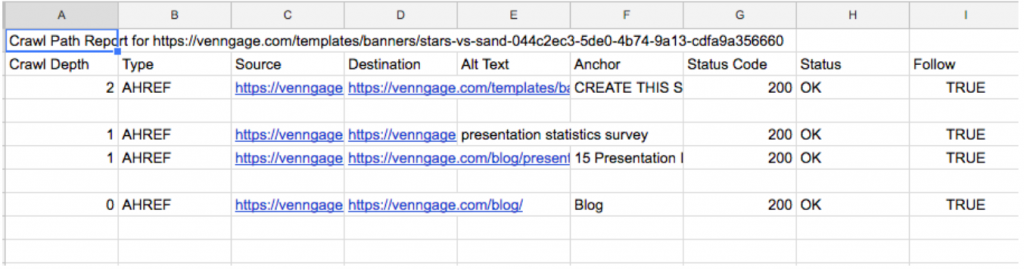
La question que vous devriez vous poser par la suite, et pour chacun de ces résultats :
“Existe-t-il un chemin plus court et tout aussi cohérent ?”
Si la réponse est oui, à vous de jouer !
Screaming Frog comprend encore bien plus d’options qui valent le coup d’être explorées. Parmi les plus intéressantes, on peut notamment mentionner :
- L’analyse de sites JavaScript (permettant d’identifier d’éventuelles ressources bloquées) ;
- L’édition de vos titres de pages et meta descriptions vita leur émulateur de « SERP Snippet » ;
- L’audit de sitemaps XML.
Et comme promis, voici quelques ressources additionnelles pour bien débuter en SEO technique :
- Les erreurs SEO les plus courantes des sites e-commerce
- SEO Technique : 16 points de contrôle pour plaire à Google [Checklist]
- Formations avancées de référencement
SEO & Growth Lead à Venngage









