 Nos certifications
Nos certificationsLe balisage de donnée structurée : comment le faire et pourquoi est-il important ?

Tout d’abord, qu’est-ce qu’une donnée structurée ? Une donnée structurée c’est l’addition d’une donnée basique (film, recette de cuisine, produit, personne, événement, entreprise, location, etc.) et d’un schéma de structuration spécifique, implémenté dans le code source de votre page web. La donnée basique structurée permet à Google de mieux comprendre votre contenu…
Qu’est-ce qu’un schéma de structuration ou schéma de balisage ?
En 2011, les 4 grands moteurs, Google, Yahoo, Yandex et Bing, se mettent d’accord sur un « lexique » commun de structuration des données basiques (film, personne, évènement, etc.). Ils créent alors le site schema.org qui regroupe tous les schémas existants les fait évoluer et en crée de nouveaux.
Donc, nous savons à présent qu’un film est une donnée basique et que schema.org peut nous aider à structurer cette donnée basique, si le schéma existe bien sûr.
Nous verrons un peu plus loin à quoi ressemblent ces schémas de balisage et comment les utiliser pour structurer vos données.
La sémantique donne du sens
Les moteurs de recherche ne sont que des agrégateurs de données, il ne s’agit que de machines qui utilisent les mêmes méthodes depuis le début.
Synthétiquement, un robot d’exploration (crawler, bot) parcourt des pages en suivant les liens qui s’y trouvent, chaque page est stockée, analysée, indexée et restituée dans le moteur de recherche si le contenu est compatible avec votre requête.
Ce fonctionnement, résumé à sa simple utilisation, ne donnait pas forcément de sens aux résultats. Au fil du temps, les techniques d’analyse des contenus se sont améliorées pour intégrer la notion de sens : de quoi parle mon article, de quoi parle mon site, que cherche l’internaute.
L’algorithme Hummingbird (Colibri) lancé en 2013 a ouvert les portes du web sémantique en modifiant l’approche du moteur vis-à-vis des requêtes des internautes.
Hummingbird (Colibri) permet au moteur de comprendre la requête, le sens de la demande ; il se base toujours sur les mots, mais essaie de détecter le souhait de résultat attendu par l’internaute en analysant l’association des mots présents dans la requête, il peut enrichir les résultats présentés par l’association de synonymes ou le remplacement de mots dans la requête.
Nous ne sommes donc plus sur un résultat « mot clef strict », mais sur un résultat répondant au sens de la demande, ce qui veut dire que des résultats peuvent apparaître alors que les contenus n’utilisent pas un terme particulier.
Il est à noter que nous sommes sur des requêtes dites de longue traîne et proche du langage naturel. Hummingbird (Colibri) ne peut être efficace que si la requête est suffisamment longue pour permettre cet exercice de compréhension, de reformulation.
Pourquoi devrais-je structurer ou baliser mes données basiques ?
Les données structurées utilisent des balises dites sémantiques, et permettent donc au moteur d’améliorer sa compréhension des données qu’il doit traiter.
Les données structurées précisent si nous parlons d’un lieu, d’une personne, d’une organisation, d’un produit, d’un événement…
Nous contextualisons notre donnée basique, nous l’encadrons de sens et offrons au moteur une compréhension simplifiée de nos contenus. En rendant nos contenus digestes, nous nous approchons de la demande de l’internaute.
De plus, baliser les données basiques permet de fournir des données enrichies au moteur et donc de modifier l’affichage présenté dans les serps.
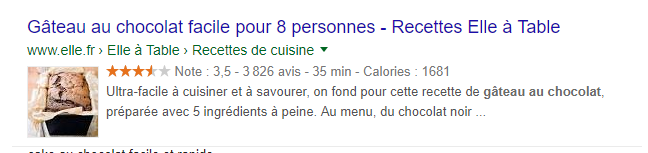
Résultat affiché pour une recette de cuisine avec les données structurées « RECIPE ». Le schéma RECIPE est le schéma dédié aux recettes de cuisine.

Résultat affiché pour une recette sans les données structurées.
Prenons un autre exemple : celui d’une page qui parle d’un livre et vend ce dernier. Sur la page de résultats du moteur de recherche, en plus du Title et de la Méta Description, pourront apparaître les éléments suivants : le prix du livre, les évaluations des lecteurs ayant acheté le livre, une photo de la couverture, etc.

Un contenu structuré couplé à une rédaction de qualité est forcément bénéfique.
À noter :
- Le fait d’apposer des données structurées ne garantit pas toujours un affichage enrichi, le moteur étant le seul décisionnaire ;
- Les données structurées ne boostent pas le positionnement, mais envoyer un contenu plus compréhensible à Google, le rendant de fait plus pertinent et donc plus en adéquation avec les requêtes des internautes, permettra certainement un nombre d’impressions plus important. Et si nous avons, en plus, un extrait riche (rich snippet) dans les serps, cela devrait nous aider à améliorer le CTR (taux de clic).
Comment dois-je structurer mes données basiques ?
De base, l’agrégation des données d’un moteur n’est qu’une suite de mots, si nous trouvons dans un contenu la phrase suivante « Mike Jagger va se produire à l’Empire State Building », on ne sait pas que Mike Jagger est une personne, que l’Empire State Building est un lieu.
Par extension ou relation, nous pourrions offrir grâce aux données structurées des sources d’informations complémentaires, contextualisant au mieux cette personne ou ce lieu :
- Mike Jagger est un chanteur, un auteur-compositeur, un musicien. Il a fondé le groupe The Rolling Stones. Il est britannique, c’est un homme, il a des enfants, il a une épouse, etc. ;
- Empire State Building est un immeuble construit en 1930, situé à New York, dans l’état de New York, il appartient à une organisation ou une personne, etc.
Nous pourrions descendre très loin dans les relations

Nous nous basons, donc, sur la bible des données structurées qu’est schema.org
Schema.org liste toutes les possibilités existantes de balisage de données structurées.
Il existe 3 formats d’encodage de ce balisage sémantique.
- MicroData et RFDa : sont des balisages que nous apposons dans le code HTML ;
- JSON-LD : est un script que nous ajoutons entre les balises <head> de notre/nos pages ou templates de page.
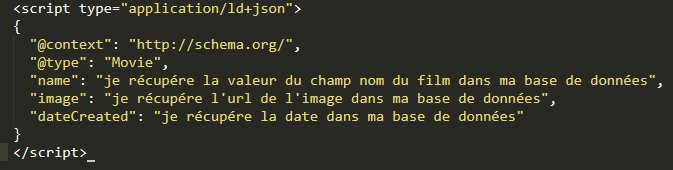
Exemple Type Movie (film) pour le texte “Ghostbusters was produced by Black Rhino in the United States”.
Code MicroData

Code RFDa

Code JSON-LD

Nous ne nous intéresserons qu’au format Json-LD, le W3C (World Wild Web Consortium) considère ce format comme la nouvelle norme à utiliser.
Détaillons le script Json-LD proposé :
| Script | Explication |
| <script type= »application/ld+json »> | Ouverture d’une balise script et indication du format |
| { | Noter l’utilisation d’accolade pour ouvrir la balise |
| « @context »: http://schema.org/, | Nous suivons le modèle de données de schema.org Noter l’@ de démarrage, les :, l’utilisation de guillemets et la virgule de fin |
| « @type »: « Movie », | Nous indiquons le type de quoi nous parlons : un film (movie) Noter l’@ de démarrage, les :, l’utilisation de guillemets et la virgule de fin |
| « name »: « Ghostbusters », | Nous indiquons le nom du film, propriété name Noter l’absence d’@, l’utilisation des :, guillemets et virgule de fin |
| « productionCompany »: { | Nous indiquons la société productrice, propriété productionCompany Noter l’absence d’@, l’utilisation des :, des guillemets et l’introduction de :{ qui permet l’imbrication d’un autre type |
| « @type »: « Organization », « name »: « Black Rhino » }, | Imbrication du type Organization (dans le type movie) et de la propriété name (qui nomme la société) Noter l’absence de virgule après le name (nous n’ajoutons pas de propriété) Noter l’utilisation de}, qui ferme l’imbrication du type Organization |
| « countryOfOrigin »: { | Nous indiquons la propriété d’origine du film CountryOfOrign Noter l’absence d’@, l’utilisation des :, des guillemets et l’introduction de : {qui permet l’imbrication d’un autre type |
| « @type »: « Country », « name »: « USA » } | Imbrication du type Country (dans le type movie) et de la propriété name (qui nomme le Pays Noter l’absence de virgule après le name (nous n’ajoutons pas de propriété) Noter l’absence de virgule après l’accolade (nous n’ajoutons plus rien) |
| } </script> | Cette accolade correspond à la fermeture de l’accolade d’ouverture situé avant @context, sans virgule, car nous n’ajoutons plus rien Nous fermons le script |
Vérifiez que vous n’avez pas fait d’erreur en utilisant l’outil de vérification de Google en copiant-collant votre code ou en testant votre URL.
Cliquez sur tester
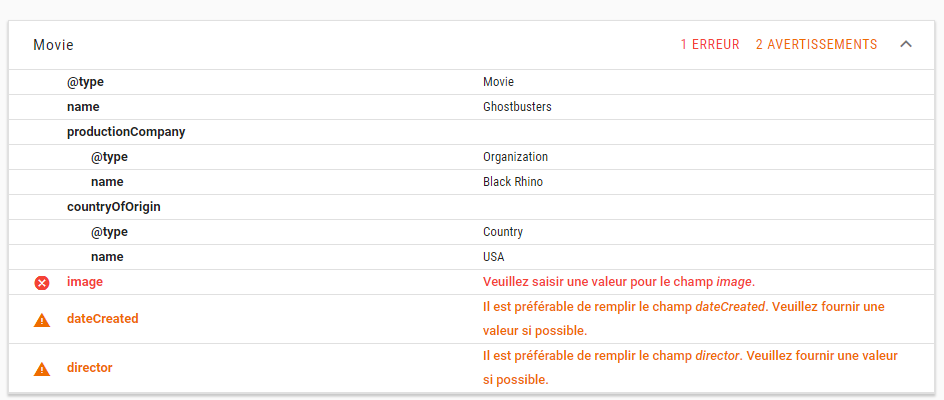
Il est intéressant de constater que le vérificateur nous demande de compléter les informations avec des champs qu’il associe habituellement au type choisi, il demande d’ajouter un visuel, une date de création et un réalisateur.
Noter également la différence de symboles : le manque d’image est considéré comme une erreur, les 2 autres comme des avertissements.
Nous allons donc modifier en conséquence le code. Rendez-vous sur votre page schema.org movie afin de connaitre la syntaxe exacte des propriétés à ajouter.
Nous découvrons que director correspond au type @person.

Nous introduisons donc une imbrication @person à notre type movie.
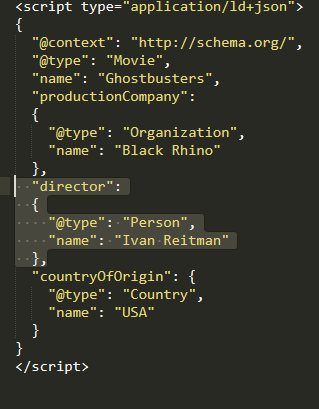
Pensez à bien ouvrir les { et à les fermer } au bon moment.
De nouveau testons notre code.
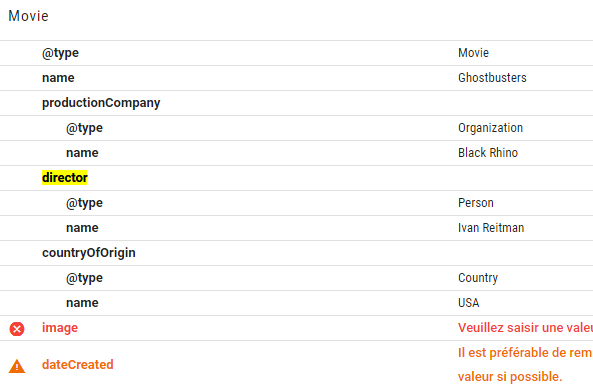
L’avertissement sur director est corrigé, nous allons compléter le code afin de ne plus avoir d’erreur ni avertissement.
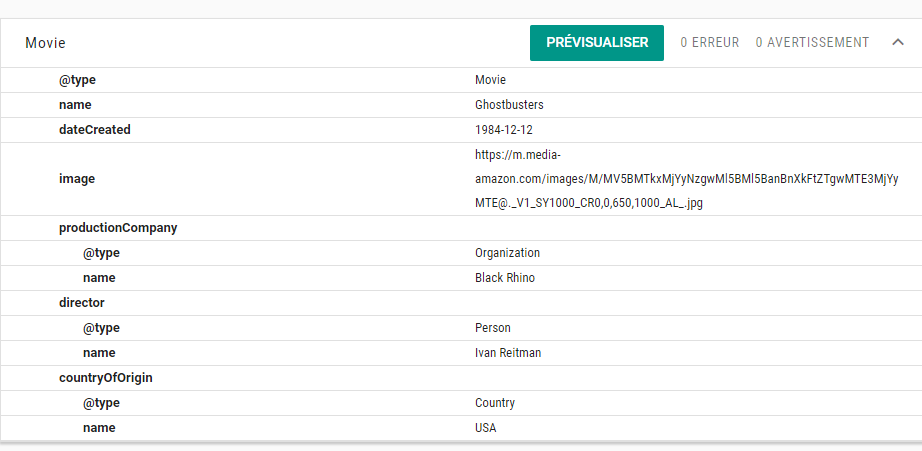
Avec l’ajout de l’image, nous avons un bouton « PRÉVISUALISER » qui est apparu, nous permettant de visualiser le résultat enrichi.

Nous pourrions ajouter des informations complémentaires à ce
code en intégrant les acteurs, une description, etc.
L’utilisation de l’outil de test est importante, car elle vous permet de valider ou non votre code.
Les scripts très longs peuvent être sujets à erreur : ajout de virgule au mauvais endroit, manque de virgule, problème d’accolade ouvrante et/ou fermante.
Le même code avec une virgule de trop après le nom du director.

Je vous invite à utiliser un éditeur de texte, tel que sublim text ou autre, avec coloration syntaxique pour préparer vos scripts et de travailler avec l’indentation qui permet de mettre en exergue les décalages entre balises, pour bien visualiser vos imbrications.
Mais comment je fais si j’ai des milliers de films ou de produits à baliser par exemple ?
Ce cas de figure est assez simple à résoudre, vous connectez votre json-ld à votre base de données, vous le faites déjà très certainement avec les balises OG (open graph).
Mais comment dois-je faire si je veux inclure des informations que je n’ai pas en base de données ?
Tout dépend du type de données que vous souhaitez ajouter, mais il faudra très certainement utiliser des bases de données de type open data et récupérer la data via des api.
Les bases de données open data, sont des bases de données ouvertes, accessibles à tous et libres de droits.
Vous trouverez des bases de données open data dans différents secteurs : transport, culture, météo, finances…. Je vous conseille de lire cet article.
Que puis-je structurer comme données ?
Si vous vous basez sur la liste de schema.org, vous n’avez que l’embarras du choix
Les plus utilisés :
- Organization : qui permet de donner des informations sur l’entreprise ;
- Person : qui permet de décrire une personne ;
- Website : qui donne des informations sur votre site ;
- Breadcrumbs : pour un fil d’ariane dans les serps ;
- Product : pour un affichage enrichi dans les serps (image, prix, etc.) ;
- Aggregate et review : pour la gestion des étoiles et avis ;
- Mais aussi des restaurants, des évènements, des musiques, des films, des business locaux, des jobs, des articles…
Comment dois-je m’y prendre pour structurer mes données ?
C’est un travail qui peut être long à préparer.
Si je devais vous proposer une méthodologie : « Partons du général vers le précis. »
Imaginons que vous possédez un site e-commerce.
- Données structurées : organization, website, breadcrumbs (générales) ;
- Données structurées template, listing de produit : itemlist (précises) ;
- Données structurées de produit : Product (précises) + avis + notes.
Chaque donnée structurée peut comporter peu ou beaucoup d’informations
Organization peut être cela :
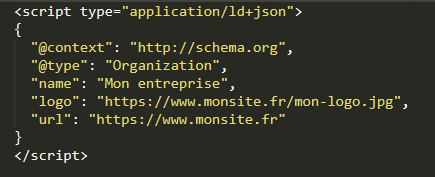
Ou cela :
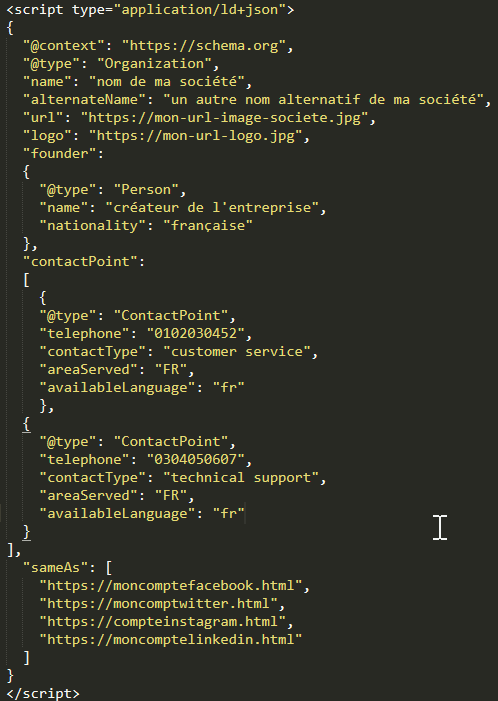
Je vous invite à identifier vos templates et pour chaque template, de réfléchir à ce que vous pourriez structurer comme données.
L’intérêt du balisage n’est pas de tout baliser, mais de baliser des informations amenant de la pertinence à l’internaute et à Google.
Prenez connaissance des consignes de Google sur le sujet.
Qui peut m’aider à structurer mes données ?
L’apprentissage de la structure d’un script Json-LD est le meilleur moyen de structurer ses données avec un maximum d’informations à envoyer. Maîtriser les imbrications ouvre une multitude de relations entre types.
Mais des solutions alternatives existent :
- Des générateurs de données structurées.
- Des agences SEO
- Google avec son outil d’aide au balisage (https://www.google.com/webmasters/markup-helper/)
Liens utiles
- https://developers.google.com/search/docs/guides/sd-policies
- https://search.google.com/structured-data/testing-tool
- https://schema.org/
- (https://www.google.com/webmasters/markup-helper/
- https://www.lebigdata.fr/open-data-definition
A propos de l’auteur :

Corinne Briche est directrice de l’agence SEOh depuis 2015. Elle évolue dans le digital depuis de nombreuses années et a fait ses armes en tant que consultante SEO Senior en agence ainsi que chez l’annonceur sur des problématiques SEO complexes à forts enjeux pour les entreprises.
Invité









